It is impractical to statically initialise all the core kernel memory structures at compile time as there are simply far too many permutations of hardware configurations. Yet to set up even the basic structures requires memory as even the physical page allocator, discussed in the next chapter, needs to allocate memory to initialise itself. But how can the physical page allocator allocate memory to initialise itself?
To address this, a specialised allocator called the Boot Memory Allocator is used. It is based on the most basic of allocators, a First Fit allocator which uses a bitmap to represent memoryĀ[Tan01] instead of linked lists of free blocks. If a bit is 1, the page is allocated and 0 if unallocated. To satisfy allocations of sizes smaller than a page, the allocator records the Page Frame Number (PFN) of the last allocation and the offset the allocation ended at. Subsequent small allocations are “merged” together and stored on the same page.
The reader may ask why this allocator is not used for the running system. One compelling reason is that although the first fit allocator does not suffer badly from fragmentationĀ[JW98], memory frequently has to linearly searched to satisfy an allocation. As this is examining bitmaps, it gets very expensive, especially as the first fit algorithm tends to leave many small free blocks at the beginning of physical memory which still get scanned for large allocations, thus making the process very wastefulĀ[WJNB95].
Table 5.1: Boot Memory Allocator API for UMA Architectures
There are two very similar but distinct APIs for the allocator. One is for UMA architectures, listed in Table ?? and the other is for NUMA, listed in Table ??. The principle difference is that the NUMA API must be supplied with the node affected by the operation but as the callers of these APIs exist in the architecture dependant layer, it is not a significant problem.
This chapter will begin with a description of the structure the allocator uses to describe the physical memory available for each node. We will then illustrate how the limits of physical memory and the sizes of each zone are discovered before talking about how the information is used to initialised the boot memory allocator structures. The allocation and free routines will then be discussed before finally talking about how the boot memory allocator is retired.
Table 5.2: Boot Memory Allocator API for NUMA Architectures
A bootmem_data struct exists for each node of memory in the system. It contains the information needed for the boot memory allocator to allocate memory for a node such as the bitmap representing allocated pages and where the memory is located. It is declared as follows in <linux/bootmem.h>:
25 typedef struct bootmem_data {
26 unsigned long node_boot_start;
27 unsigned long node_low_pfn;
28 void *node_bootmem_map;
29 unsigned long last_offset;
30 unsigned long last_pos;
31 } bootmem_data_t;
The fields of this struct are as follows:
Each architecture is required to supply a setup_arch() function which, among other tasks, is responsible for acquiring the necessary parameters to initialise the boot memory allocator.
Each architecture has its own function to get the necessary parameters. On the x86, it is called setup_memory(), as discussed in Section 2.2.2, but on other architectures such as MIPS or Sparc, it is called bootmem_init() or the case of the PPC, do_init_bootmem(). Regardless of the architecture, the tasks are essentially the same. The parameters it calculates are:
Once the limits of usable physical memory are discovered by setup_memory(), one of two boot memory initialisation functions is selected and provided with the start and end PFN for the node to be initialised. init_bootmem(), which initialises contig_page_data, is used by UMA architectures, while init_bootmem_node() is for NUMA to initialise a specified node. Both function are trivial and rely on init_bootmem_core() to do the real work.
The first task of the core function is to insert this pgdat_data_t into the pgdat_list as at the end of this function, the node is ready for use. It then records the starting and end address for this node in its associated bootmem_data_t and allocates the bitmap representing page allocations. The size in bytes, hence the division by 8, of the bitmap required is calculated as:
mapsize = ((end_pfn - start_pfn) + 7) / 8
The bitmap in stored at the physical address pointed to by
bootmem_data_t→node_boot_start and the virtual address to the map is placed in bootmem_data_t→node_bootmem_map. As there is no architecture independent way to detect “holes” in memory, the entire bitmap is initialised to 1, effectively marking all pages allocated. It is up to the architecture dependent code to set the bits of usable pages to 0 although, in reality, the Sparc architecture is the only one which uses this bitmap. In the case of the x86, the function register_bootmem_low_pages() reads through the e820 map and calls free_bootmem() for each usable page to set the bit to 0 before using reserve_bootmem() to reserve the pages needed by the actual bitmap.
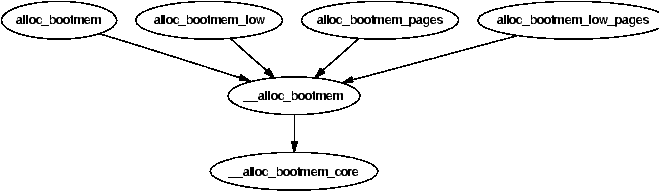
The reserve_bootmem() function may be used to reserve pages for use by the caller but is very cumbersome to use for general allocations. There are four functions provided for easy allocations on UMA architectures called alloc_bootmem(), alloc_bootmem_low(), alloc_bootmem_pages() and alloc_bootmem_low_pages() which are fully described in Table ??. All of these macros call __alloc_bootmem() with different parameters. The call graph for these functions is shown in in Figure 5.1.
Figure 5.1: Call Graph: alloc_bootmem()
Similar functions exist for NUMA which take the node as an additional parameter, as listed in Table ??. They are called alloc_bootmem_node(), alloc_bootmem_pages_node() and alloc_bootmem_low_pages_node(). All of these macros call __alloc_bootmem_node() with different parameters.
The parameters to either __alloc_bootmem() and __alloc_bootmem_node() are essentially the same. They are
The core function for all the allocation APIs is __alloc_bootmem_core(). It is a large function but with simple steps that can be broken down. The function linearly scans memory starting from the goal address for a block of memory large enough to satisfy the allocation. With the API, this address will either be 0 for DMA-friendly allocations or MAX_DMA_ADDRESS otherwise.
The clever part, and the main bulk of the function, deals with deciding if this new allocation can be merged with the previous one. It may be merged if the following conditions hold:
Regardless of whether the allocations may be merged or not, the pos and offset fields will be updated to show the last page used for allocating and how much of the last page was used. If the last page was fully used, the offset is 0.
In contrast to the allocation functions, only two free function are provided which are free_bootmem() for UMA and free_bootmem_node() for NUMA. They both call free_bootmem_core() with the only difference being that a pgdat is supplied with NUMA.
The core function is relatively simple in comparison to the rest of the allocator. For each full page affected by the free, the corresponding bit in the bitmap is set to 0. If it already was 0, BUG() is called to show a double-free occured. BUG() is used when an unrecoverable error due to a kernel bug occurs. It terminates the running process and causes a kernel oops which shows a stack trace and debugging information that a developer can use to fix the bug.
An important restriction with the free functions is that only full pages may be freed. It is never recorded when a page is partially allocated so if only partially freed, the full page remains reserved. This is not as major a problem as it appears as the allocations always persist for the lifetime of the system; However, it is still an important restriction for developers during boot time.
Late in the bootstrapping process, the function start_kernel() is called which knows it is safe to remove the boot allocator and all its associated data structures. Each architecture is required to provide a function mem_init() that is responsible for destroying the boot memory allocator and its associated structures.
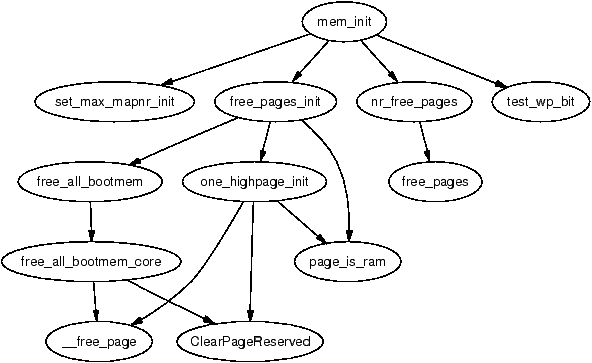
Figure 5.2: Call Graph: mem_init()
The purpose of the function is quite simple. It is responsible for calculating the dimensions of low and high memory and printing out an informational message to the user as well as performing final initialisations of the hardware if necessary. On the x86, the principal function of concern for the VM is the free_pages_init().
This function first tells the boot memory allocator to retire itself by calling free_all_bootmem() for UMA architectures or free_all_bootmem_node() for NUMA. Both call the core function free_all_bootmem_core() with different parameters. The core function is simple in principle and performs the following tasks:
At this stage, the buddy allocator now has control of all the pages in low memory which leaves only the high memory pages. After free_all_bootmem() returns, it first counts the number of reserved pages for accounting purposes. The remainder of the free_pages_init() function is responsible for the high memory pages. However, at this point, it should be clear how the global mem_map array is allocated, initialised and the pages given to the main allocator. The basic flow used to initialise pages in low memory in a single node system is shown in Figure 5.3.
Figure 5.3: Initialising mem_map and the Main Physical Page Allocator
Once free_all_bootmem() returns, all the pages in ZONE_NORMAL have been given to the buddy allocator. To initialise the high memory pages, free_pages_init() calls one_highpage_init() for every page between highstart_pfn and highend_pfn. one_highpage_init() simple clears the PG_reserved flag, sets the PG_highmem flag, sets the count to 1 and calls __free_pages() to release it to the buddy allocator in the same manner free_all_bootmem_core() did.
At this point, the boot memory allocator is no longer required and the buddy allocator is the main physical page allocator for the system. An interesting feature to note is that not only is the data for the boot allocator removed but also all code that was used to bootstrap the system. All initilisation function that are required only during system start-up are marked __init such as the following;
321 unsigned long __init free_all_bootmem (void)
All of these functions are placed together in the .init section by the linker. On the x86, the function free_initmem() walks through all pages from __init_begin to __init_end and frees up the pages to the buddy allocator. With this method, Linux can free up a considerable amount of memory that is used by bootstrapping code that is no longer required. For example, 27 pages were freed while booting the kernel running on the machine this document is composed on.
The boot memory allocator has not changed significantly since 2.4 and is mainly concerned with optimisations and some minor NUMA related modifications. The first optimisation is the addition of a last_success field to the bootmem_data_t struct. As the name suggests, it keeps track of the location of the last successful allocation to reduce search times. If an address is freed before last_success, it will be changed to the freed location.
The second optimisation is also related to the linear search. When searching for a free page, 2.4 test every bit which is expensive. 2.6 instead tests if a block of BITS_PER_LONG is all ones. If it's not, it will test each of the bits individually in that block. To help the linear search, nodes are ordered in order of their physical addresses by init_bootmem().
The last change is related to NUMA and contiguous architectures. Contiguous architectures now define their own init_bootmem() function and any architecture can optionally define their own reserve_bootmem() function.