
See the following diagram for rough rules of thumb for RCU's applicability:
As shown in the blue box, RCU works best if you have read-mostly data where stale and inconsistent data is permissible (but see below for more information on stale and inconsistent data). The canonical example of this case in the Linux kernel is routing tables. Because it may have taken many seconds or even minutes for the routing updates to propagate across Internet, the system has been sending packets the wrong way for quite some time. Having some small probability of continuing to send some of them the wrong way for a few more milliseconds is almost never a problem.
If you have a read-mostly workload where consistent data is required, RCU works well, as shown by the green box. One example of this case is the Linux kernel's mapping from user-level System-V semaphore IDs to the corresponding in-kernel data structures. Semaphores tend to be used far more frequently than they are created and destroyed, so this mapping is read-mostly. However, it would be erroneous to perform a semaphore operation on a semaphore that has already been deleted. This need for consistency is handled by using the lock in the in-kernel semaphore data structure, along with a “deleted” flag that is set when deleting a semaphore. If a user ID maps to an in-kernel data structure with the “deleted” flag set, the data structure is ignored, so that the user ID is flagged as invalid.
Although this requires that the readers acquire a lock for the data structure representing the semaphore itself, it allows them to dispense with locking for the mapping data structure. The readers therefore locklessly traverse the tree used to map from ID to data structure, which in turn greatly improves performance, scalability, and real-time response.
As indicated by the yellow box, RCU can also be useful for read-write workloads where consistent data is required, although usually in conjunction with a number of other synchronization primitives. For example, the dentry cache in recent Linux kernels uses RCU in conjunction with sequence locks, per-CPU locks, and per-data-structure locks to allow lockless traversal of pathnames in the common case. Although RCU can be very beneficial in this read-write case, such use is often more complex than that of the read-mostly cases.
Finally, as indicated by the red box, update-mostly workloads requiring
consistent data are rarely good places to use RCU, though there are some
exceptions.
In addition, within the Linux kernel, the SLAB_DESTROY_BY_RCU
slab-allocator flag provides type-safe memory to RCU readers, which can
greatly simplify non-blocking synchronization and other lockless
algorithms.
So what exactly is meant by stale and inconsistent data? One helpful way of looking at this important question is shown below:
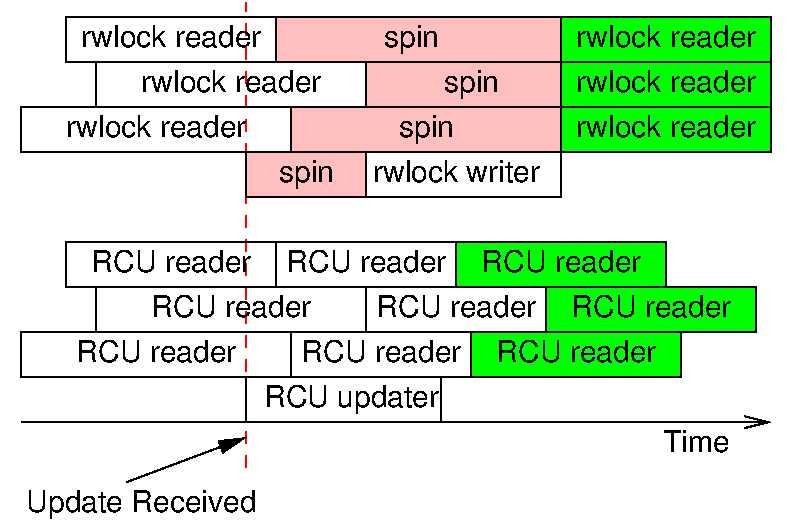
This diagram compares reader-writer locking, which provides consistency and avoids stale data, with RCU, which does not. As can be seen in the upper portion of the diagram, the way that reader-writer locking avoids inconsistency and staleness is by mutual exclusion: It refuses to allow readers and writers to look at the same data at the same time. But this comes at a large cost in terms of performance and scalability, as can be seen by the boxes labeled “spin” in the upper portion of the diagram.
In contrast, RCU allows readers and updaters to run concurrently, which means that RCU readers actually see the update sooner than the rwlock readers do. Therefore, in a global sense that includes the outside world as well as the computer itself, RCU readers see data that is actually fresher and more consistent with the outside world than do rwlock readers.
In other words, the concepts of “consistency” and “stale data” are strictly internal to the system, so that RCU sacrifices internal freshness and consistency to gain improved external freshness and consistency, along with greatly improved performance, scalability, and real-time response.